In a desperate attempt to make myself look cool and connected, on my lab webpage I wrote that my research
...focuses on the application of fMRI and computational modeling in order to further understand prediction and evaluation mechanisms in the medial prefrontal cortex and associated cortical and subcortical areas...
Lies. By God, lies. I know as much about computational modeling as I do about how Band-Aids work or what is up an elephant's trunk. I had hoped that I would grow into the description I wrote for myself; but alas, as with my pathetic attempts to wake up every morning before ten o'clock, or my resolution to eat vegetables at least once a week, this also has proved too ambitious a goal; and slowly, steadily, I find myself engulfed in a blackened pit of despair.
Computational modeling - mystery of mysteries. In my academic youth I observed how cognitive neuroscientists outlined computational models of how certain parts of the brain work; I took notice that their work was received with plaudits and the feverish adoration of my fellow nerds; I then burned with jealousy upon seeing these modelers at conferences, mobs of slack-jawed science junkies surrounding their posters, trains of odalisques in their wake as they made their way back to their hotel chambers at the local Motel 6 and then proceeded to sink into the ocean of their own lust. For me, learning the secrets of this dark art meant unlocking the mysteries of the universe; I was convinced it would expand my consciousness a thousandfold.
I work with a computational modeler in my lab - he is the paragon of happiness. He goes about his work with zest and vigor, modeling anything and everything with confidence; not for a moment does self-doubt cast its shadow upon his soul. He is the envy of the entire psychology department; he has a spring in his step and a knowing wink in his eye; the very mention of his name is enough to make the ladies' heads turn. He has it all, because he knows the secrets, the joys, the unbounded ecstasies of computational modeling.
Desiring to have this knowledge for myself, I enrolled in a class about computational modeling. I hoped to gain some insight; some clarity. So far I have only found myself entangled in a confused mess. I hold onto the hope that through perseverance something will eventually stick.
However, the class has provided useful resources to get the beginner started. A working knowledge of the electrochemical properties of neurons is essential, as is modeling their effects through software such as Matlab. The Book of Genesis is a good place to get started with sample code and to catch up on the modeling argot; likewise, the CCN wiki over at Colorado is a well-written introduction to the concepts of modeling and how it applies to different cognitive domains.
I hope that you get more out of them than I have so far; I will post more about my journey as the semester goes on.
In a previous post I outlined how to overlay results generated by SPM or FSL onto a SUMA surface and published a tutorial video on my Techsmith account. However, as I am consolidating all of my tutorials onto Youtube, this video has been uploaded to Youtube instead.
There are few differences between this tutorial and the previous one; however, it is worth reemphasizing that, as the results have been interpolated onto another surface, one should not perform statistical analyses on these surface maps - use them for visualization purposes only. The correct approach for surface-based analyses is to perform all of your preprocessing and statistics on the surface itself, a procedure which will later be discussed in greater detail.
A couple of other notes:
1) Use the '.' and ',' keys to toggle between views such as pial, white matter, and inflated surfaces. These buttons were not discussed in the video.
2) I recommend using SPM to generate cluster-corrected images before overlaying these onto SUMA. That way, you won't have to mess with the threshold slider in order to guess which t-value cutoff to use.
A couple weeks ago I blogged hard about a problem presented by lesion studies of the anterior cingulate cortex (ACC), a broad swath of cortex shown to be involved in aspects of cognitive control such as conflict monitoring (Botvinick et al, 2001) and predicting error likelihood (Brown & Braver, 2005). Put simply: The annihilation of this region, either through strokes, infarctions, bullet wounds, or other cerebral insults, does not result in a deficit of cognitive control, as measured through reaction time (RT) in response to a variety of tasks, such as Stroop tasks - a task that requires overriding prepotent responses to a word presented on a screen, as opposed to the color of the ink that the word is written in - and paradigms which involve task-switching.
In particular, a lesion study by Fellows & Farah (2005) did not find a significant RT interaction of group (either controls or lesion patients) by condition (either low or high conflict in a Stroop task; i.e., either the word and ink color matched or did not match), suggesting that the performance of the lesion patients was essentially the same as the performance of controls. This in turn prompted the question of whether the ACC was really necessary for cognitive control, since those without it seemed to do just fine, and were about a pound lighter to boot. (Rimshot)
However, a recent study by Sheth et al (2012) in Nature examined six lesion patients undergoing cingulotomy, a surgical procedure which removes a localized portion of the dorsal anterior cingulate (dACC) in order to alleviate severe obsessive-compulsive symptoms, such as the desire to compulsively check the amount of hits your blog gets every hour. Before the cingulotomy, the patients performed a multisource interference task designed to elicit cognitive control mechanisms associated with dACC activation. The resulting cingulotomy overlapped with the peak dACC activation observed in response to high-conflict as contrasted with low-conflict trials (Figure 1).
Figure 1 reproduced from Sheth et al (2012). d) dACC activation in response to conflict. e) arrow pointing to lesion site
Furthermore, the pattern of RTs before surgery followed a typical response pattern replicated over several studies using this task: RTs were faster for trials immediately following trials of a similar type - such as congruent trials following congruent trials, or incongruent trials following incongruent trials - and RTs were slower for trials which immediately followed trials of a different type, a pattern known as the Gratton effect.
The authors found that global error rates and RTs were similar before and after the surgery, dovetailing with the results reported by Fellows & Farah (2005); however, the modulation of RT based on previous trial congruency or incongruency was abolished. These results suggest that the ACC functions as a continuous updating mechanism modulating responses based on the weighted past and on trial-by-trial cognitive demands, which fits into the framework posited by Dosenbach (2007, 2008) that outlines the ACC as part of a rapid-updating cingulo-opercular network necessary for quick and flexible changes in performance based on task demands and performance history.
a) Pre-surgical RTs in response to trials of increasing conflict. b, c) Post-surgical RTs showing no difference between low-conflict trials preceded by either similar or different trial types (b), and no RT difference between high-conflict trials preceded by either similar or different trial types (c).
Above all, this experiment illustrates how lesion studies ought to be conducted. First, the authors identified a small population of subjects about to undergo a localized surgical procedure to lesion a specific area of the brain known to be involved in cognitive control; the same subjects were tested before the surgery using fMRI and during surgery using single-cell recordings; and interactions were tested which had been overlooked by previous lesion studies. It is an elegant and simple design; although I imagine that testing subjects while they had their skulls split open and electrodes jammed into their brains was disgusting. The things that these sickos will do for high-profile papers.
(This study may be profitably read in conjunction with a recent meta-analysis of lesion subjects (Gläscher et al, 2012; PNAS) dissociating cortical structures involved in cognitive control as opposed to decision-making and evaluation tasks. I recommend giving both of these studies a read.)
I've been uploading more videos recently; the first, an impromptu by Schubert, as I have been on a Schubert kick recently; the second, an instrumental cover of one of Ben Folds's most popular songs - because there aren't enough covers of it out there already.
Once upon a time one of my friends, succumbing to a brief spell of melodrama, announced to a circle of us gathered around him that he didn't believe in love. I wasn't sure whether this was supposed to shock us, or intrigue us, or both, as this opinion is widespread and commonplace among people his age. Often they are either cynical about the nature of love, or cannot comprehend how you can presume to care about another without having at least some amount of selfishness; much more interesting, and considerably less intimidating, is to break it down into its biological components to make it more approachable. Attempting to talk about love by referring to a work of art such as Anna Karenina or The Red and The Black is old hat; better not to try.
We are of course talking about romantic passion, that most well-known yet least understood of all the different shades of love. Far from it that I should try to attempt to define it here; however, I can't help but be puzzled as to why anyone should question whether or not it exists, when it is in plain sight all around, if we have eyes to see. And possibly the best example I can point to is a piece of music: the Franck Violin Sonata.
Yesterday I had the opportunity to hear this piece live. My high school piano teacher and a violin professor at the Jacobs School were about to go on tour, and had this piece as part of the program, in addition to sonatas by Mozart and Stravinsky; they wanted to give it a run-through in one of the empty recital halls, and I was invited to a private performance. Of course I said yes; although I must have listened to recordings of this piece dozens of times, nothing beats the real thing. I sat back, relaxed, and began to listen.
Those mysterious, sparse, magical opening chords; reader, there is nothing that will send a greater chill down your spine, nothing that will disarm you so completely, as those first few notes. And then, as the violin enters with her lilting theme, you become aware that this is more than a piece of music; it's a story about two souls wandering; then catching sight of each other; and then realizing, with a resounding dominant chord - the universal language of yearning - that they have found each other at last. And who has not felt this way? Even with all of the false starts, the inevitable disappointments, the tragic misunderstandings, the whirlwinds of passion that surround the rest of the piece and portray our own relationships; even with all of this, who on earth has never felt this way?
Much could be said about the other movements, but here I will only focus on the last; for it is the most important by far, and both validates and affirms everything that has come before it. The opening canon - possibly the finest example of this style of counterpoint - is a duet of the utmost tenderness, and proves why this sonata is so beloved and highly regarded. The middle section is stormy and full of pathos, transforming the opening themes until they are almost unrecognizable; but the storm clears, the lovers are reunited, and both rush to an exuberant conclusion.
I leave you with one of the supreme achievements of chamber music. I hope that you will find the time to listen to it at least once through, from beginning to end; and then come back later and listen to it time and again throughout your life, until it becomes a part of your emotional world. Enjoy.
(P.S. This piece is also hard as fuck to play; much respect for those of you who have performed it.)
One question I frequently hear - besides "Why are you staring at me like that?" - is, "Should I optimize my experimental design?" This question is foolish. As well ask man what he thinks of Nutella. Optimal experimental designs are essential to consider before creating an experiment, in order to ensure that there is a balance between the number of trials, the duration of the experiment, and the estimation efficiency. Optseq is one such tool which allows the experimenter to maximize all three.
Optseq, a tool developed by the good people over at MGH, helps the user order the presentation of experimental conditions or stimuli in order to optimize the estimation of beta weights for a given condition or a given contrast. By providing a list of the experimental conditions, the length of the experiment, the TR, and how long and how frequent the experimental conditions last, optseq will generate schedules of stimuli presentation that maximizes the power of the design, both through reducing variance due to noise and increasing the efficiency of estimating beta weights. This is especially important in event-related designs, which are discussed in greater detail below.
Chapter 1: Slow Event-Related Designs
Slow event-related designs refer to experimental paradigms in which the hemodynamic response function (HRF) for a given condition does not overlap with another condition's HRF. For example, let us say that we have an experiment in which IAPS photos are presented to the subject at certain intervals. Let us also say that there are three classes of photos (or conditions): 1) Disgusting pictures (DisgustingPic); 2) Attractive pictures (AttractivePic); and neutral pictures (NeutralPic). The order in which these pictures are presented will be at a long enough time interval so that the HRFs do not overlap, as shown in the following figure (Note: All of the following figures are taken from the AFNI website; all credit and honor is theirs. They may find these later and try to sue me, but that is a risk I am willing to take):
The interstimulus time interval (ITI) in this example is 15 seconds, allowing enough time for the entire HRF to rise and decay, and therefore allow the experimenter to estimate a beta weight for each condition individually without worrying about overlap in the HRFs. (The typical duration of an HRF, from onset to decay back to baseline, is roughly 12 seconds, with a long period of undershoot and recovery thereafter). However, slow event-related designs suffer from relatively long experimental durations, since the time after each stimulus presentation has to allow enough time for the HRF to decay to baseline levels of activity. Furthermore, the subject may become bored after such lengthy "null" periods, and may develop strategies (aka, "sets") when the timing is too predictable. Therefore, quicker stimulus presentation is desirable, even if it leads to overlap in the conditions's HRFs.
Chapter 2: Rapid (or Fast) Event-Related Designs
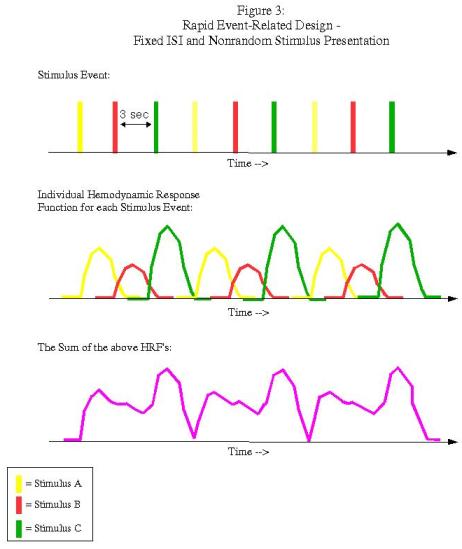
Rapid event-related designs refer to experimental paradigms in which the ISI between conditions is short enough so that the hemodynamic response function (HRF) for a given condition overlaps with another condition's HRF. Theoretically, given the assumption of linearity of overlapping HRFs, this shouldn't be a problem, and the contribution of each condition's HRF can be determined through a process known as deconvolution. However, this can be an issue when the ISI's are fixed and the presentation of stimuli is fixed as well:
In this example, each condition follows the other in a fixed pattern: A followed by B followed by C. However, the resulting signal arising from the combination of HRFs (shown in purple in the bottom graph) is impossible to disentangle; we have no way of knowing, at any given time point, what amount of the signal is due to condition A, B, or C. In order to resolve this, we must randomize the presentation of the stimuli and also the duration of the ISI's (a process known as "jittering"):
Now we have enough variability so that we can deconvolve the contribution of each condition to the overall signal, and estimate a beta weight for each condition. This is the type of experimental design that optseq deals with.
Chapter 3: Optseq
In order to use optseq, first download the software from the MGH website (or, just google "optseq" and click on the first hit that comes up). Put the shell script into a folder somewhere in your path (such as ~/abin, if you have already downloaded AFNI) so that it will execute from anywhere within the shell. After you have done this you may also want to type "rehash" at the command line in order to update the paths. Then, type "optseq2" to test whether the program executes or not (if it does, you should get the help output, which is generated when no argument are given).
Optseq needs four pieces of information: 1) The number of time points in a block of your experiment; 2) The TR; 3) A permissible range of the minimum and maximum amounts of time after presentation of a stimulus and the start of the next (aka, the post-stimulus delay, or PSD); and 4) How many conditions there are in your experiment, as well as how long they are per trial and how many trials there are per block. Optseq will then generate a series of schedules that randomize the order of the ITI's and the stimuli in order to find the maximum design efficiency.
Using the IAPS photos example above, let us also assume that there are: 1) 160 time points in the experiment; 2) a TR of 2 seconds; 3) A post-stimulus window of 20 seconds to capture the hemodynamic response; 3) Jitters ranging from 2 to 8 seconds; and 4) The three conditions mentioned above, each last 2 seconds per trial, and with 20 instances of DisgustingPic, 15 instances of AttractivePic, and 30 instances of NeutralPic. Furthermore, let us say that we wish to keep the top three schedules generated by optseq, each prefixed by the word IAPS, and that we want to randomly generate 1000 schedules.
Lastly, let us say that we are interested in a specific contrast - for example, calculating the difference in activation between the conditions disgustingPic and attractivePic.
This will generate stimuli presentation schedules and only keep the top three; examples of these schedules, as well as an overview of how the efficiencies are calculated, can be seen in the video.
Chapter 4: The Reckoning - Comparison of optseq to 1d_tool.py
Optseq is a great tool for generating templates for stimuli presentation. However, if only one schedule is generated and applied to all blocks and all subjects, there is the potential for ordering effects to be confounded with your design, however minimal that possibility may be. If optseq is used, I recommend that a unique schedule be generated for each block, and then counterbalance or randomize those blocks across subjects. Furthermore, you may also want to consider randomly sampling the stimuli and ITI's and simulate several runs of your experiment, and then run them through AFNI's 1d_tool.py in order to see how efficient they are. With a working knowledge of optseq and 1d_tool.py, in addition to a steady diet of HotPockets slathered with Nutella, you shall soon become invincible.
With this tutorial we begin to enter into AFNI territory, as the more advanced Unix commands and procedures are necessary for running an AFNI analysis. First, we cover the basics of for loops. For loops in fMRI analysis are used to loop over subjects and execute preprocessing and postprocessing scripts for each subject individually. (By the way, I've heard of preprocessing and I've heard of postprocessing; but where does plain, regular processing take place? Has anyone ever thought of that? Does it ever happen at all? I feel like I'm taking crazy pills here.)
Within the t-shell (and I use the t-shell here because it is the default shell used by AFNI), a for loop has the following syntax:
foreach [variableName] ( [var1] [var2]...[varN]) [Executable steps go here]
end So, for example, if I wanted to loop over a list of values and have them assigned to variable "x" and then return those values, I could do something like the following: foreach x (1 2 3 4 5) echo $x end Which would return the following: 1 2 3 4 5 Notice in this example that the for loop executes the line of code "echo $x", and assigns a new value to x for each step of the for loop. You can imagine how useful this can be when extended to processing individual subjects for an analysis, e.g.: foreach subj ( subj1 subj2 subj3...subjN ) tcsh afni_proc.py $subj end
That is all you need to process a list of subjects automatically, and, after a little practice, for loops are easy and efficient to use. The same logic of for loops applies to FSL analyses as well, if you were to apply a feat or gfeat command to a list of feat directories. In the next batch of tutorials, we will begin covering the basics of AFNI, and eventually see how a typical AFNI script incorporates the use of for loops in its analysis.
The second part of the tutorial covers shell scripting. A shell script executes a series of commands within a text file (or, more formally, shell script), allowing the user more flexibility in applying a complex series of commands that would be unwieldy to type out in the command line. Just think of it as dumping everything you would have typed out explicitly into the command line, into a tidy little text file that can be altered as needed and executed repeatedly.
Let us say that we wish to execute the code in the previous example, and update it as more subjects are acquired. All that would be added would be a shebang, in order to specify the shell syntax used in the script:
#!/bin/tcsh foreach subj (subj1 subj2 subj3) tcsh afni_proc.py $subj end
After this file has been saved, make sure that it has executable permissions. Let's assume that the name of our shell script is AFNI_procScript.sh; in order to give it executable permissions, simply type
chmod +x AFNI_procScript.sh
And it should be able to be run from the command line. In order to run it, type the "./" before the name of the script, in order to signify that it should be executed from the shell, e.g.:
./AFNI_procScript.sh
Alternatively, if you wish to override the shebang, you can type the name of the shell you wish to execute the script. So, for example, if I wanted to use bash syntax, I could type:
bash AFNI_procScript.sh
However, since the for loop is written in t-shell syntax, this would return an error.
Due to popular demand, an optseq tutorial will be uploaded tomorrow. Comparisons between the output of optseq and AFNI's 1d_tool.py is encouraged, as there is no "right" sequence of stimulus presentations you should use; only reasonable ones.