
Sunday, January 29, 2017
Are All FMRI Results Wrong?
False positive rates in science have been an issue recently; and although we all had a good laugh when it happened to the social psychologists two years ago, now that it's happening to us, it's not so funny.
Anders Eklund and colleagues published a paper last summer showing that cluster correction - one method that FMRI researchers use to test whether their results are statistically significant or not - can lead to high false positive rates, or saying that a result is real, when actually it is a random occurrence that looks like a real result.
Their calculations showed that about 10% of FMRI studies are affected by this error (http://tinyurl.com/jaomsgs). However, keep in mind that even if a study is at risk for reporting a false positive, doesn't mean that their result is necessarily spurious. As with all results, one must go to the original study and take into account the rigor of the experimental design and whether the result looks legitimate.
These flaws have been addressed in recent versions of AFNI, an FMRI software package. The steps to use these updated programs can be found on the blog here: http://tinyurl.com/j5vafsb
Thursday, January 19, 2017
Commentary on Cluster Failure: Inflated False Positives in FMRI

Why did the old Folly end now, and no later? Why did the modern Wisdom begin now, and no sooner?
-Rabelais, Prologue to Book V
=======================
Academia, like our nation's morals, seems to be forever in peril. When I first heard of the replication crisis - about how standards are so loose that a scientist can't even replicate what he ate for breakfast three days ago, much less reproduce another scientist's experiment - I was reminded of my grandpa. He once complained to me that colleges today are fleshpots of hedonism and easy sex. Nonsense, I said. Each year literally tens of students graduate with their virtue intact.
Nonetheless, the more I learned about the replication crisis, the more alarmed I became. You know a crisis is serious when it has its own Wikipedia page, and when its sister phrase "questionable research practices" gets its own acronym: QRP (pronounced "Quirp"). These practices range from data "peeking" - ogling a p-value before she's half-dressed - to fabricating data, one of academia's gravest sins. (Apparently grant agencies have gotten very picky about researchers lying about their results and wasting millions of dollars.) One of my friends suggested campaigning for a War on QRPs, with scientists in white labcoats stamping out QRPs like cockroaches. Who knows - someday QRP Exterminator may become as respected and honorable a position as Lab Manager.
One such QRP was recently flushed out of hiding in an article by Eklund and colleagues published in the journal PNAS (pronounced "P-NAS"), with the klieg lights thrown on cluster correction, the most common FMRI multiple comparison technique. If you're in a neuroimaging lab, or if you've read about FMRI in a magazine, you've come across these clusters - splotches of reds and yellows, color-coded to show the strength of the result. They look attractive, especially on glossy magazine pages, and they make for good copy.
 |
| Relative popularity of different correction methods. The majority use cluster correction; a smaller percentage use voxel-based thresholding (i.e., correcting for the total number of voxels in the brain); and the remainder do not use correction. Men who don't use correction claim that it feels more spontaneous and natural. Adapted from Woo et al. (2014) |
There is another reason for the popularity of clusters: As each FMRI dataset contains tens or hundreds of thousands of voxels, and as each voxel is similar to its neighbor, it is useful to test whether a cluster of voxels is significant instead of each voxel individually. This increases the sensitivity of detecting activation, although at the cost of reduced spatial sensitivity. If I point to a cloud of smoke in the distance you will assume there is a fire somewhere, although seeing the cloud itself gives you only a vague idea of where or how big the fire is - or, for that matter, whether its the result of a dozen individual campfires, or of a single inferno.
Problems with Cluster Correction
The authors don't take issue with cluster correction per se; rather, they claim that the assumptions behind the technique, and how the correction is used, can lead to inflated false positives. In other words, using cluster correction makes one more likely to say that a cluster represents a true activation, when the cluster is actually noise. The assumptions they question are:
1) That spatial smoothness is constant over the brain; and
2) That spatial autocorrelation looks like a Gaussian distribution.
Spatial smoothness is in fact not constant; it varies over the brain. Midline regions such as the precuneus, anterior cingulate cortex, and prefrontal areas show more spatial smoothness than the the outer regions - possibly because the midline areas of cortex, with the gray matter of the hemispheres in close proximity to each other, have similar structure and similar timecourses of activity which are averaged together. The underestimation of spatial smoothness in these areas can lead to inflated false positives, which may be why midline areas (such as the anterior cingulate cortex) turn up as a significant result much more often than other areas.
 |
| Effects of spatial smoothing at different smoothing sizes, or kernels. The larger the smoothing kernel, the more that adjacent voxels are blurred together, resulting in greater similarity of spatial structure and also of the timecourse of activity. |
It is the second assumption, however, which is the main cause behind the increase in false positives demonstrated in the Eklund paper. The idea behind spatial autocorrelation is simple: A voxel is more similar to its immediate neighbors and less similar to voxels farther away, the similarity falling off in concentric spheres around a given voxel. This correlation between each voxel and its neighbors is traditionally modeled with a Gaussian distribution - the same bell-shaped curve that models most distributions, such as IQ or height - when in reality the autocorrelation distribution has much thicker tails:
 |
| Comparison of the Gaussian distribution (green) with the empirical ACF (black) and mixed model of a Gaussian and exponential distribution (red). Note the increasing discrepancy between the Gaussian distribution and the empirical distribution around 5mm, with the thicker tails of the empirical distribution suggesting that more distant voxels are more correlated than is assumed under traditional clustering methods. |
When the authors ran simulations on large datasets under different experimental conditions (e.g., block design and event-related), they found that this assumption of a Gaussian shape led to false positives far above the expected 5% rate across all the major software packages (SPM, AFNI, and FSL). The commonly used p = 0.01 threshold for the individual voxels of the cluster led to much higher false positive rates than a more stringent p = 0.001 threshold. (Notably, permutation testing, a nonparametric method that does not rely on assumptions of normality, did not show any substantial difference in false positives under any conditions.) These inflated false positive rates led to the following figure, which was picked up by the popular media and discussed in a fair, evenhanded way which emphasized that although false positive rates could be increased in some cases, it would be hasty to conclude that all neuroimaging results are wrong.*
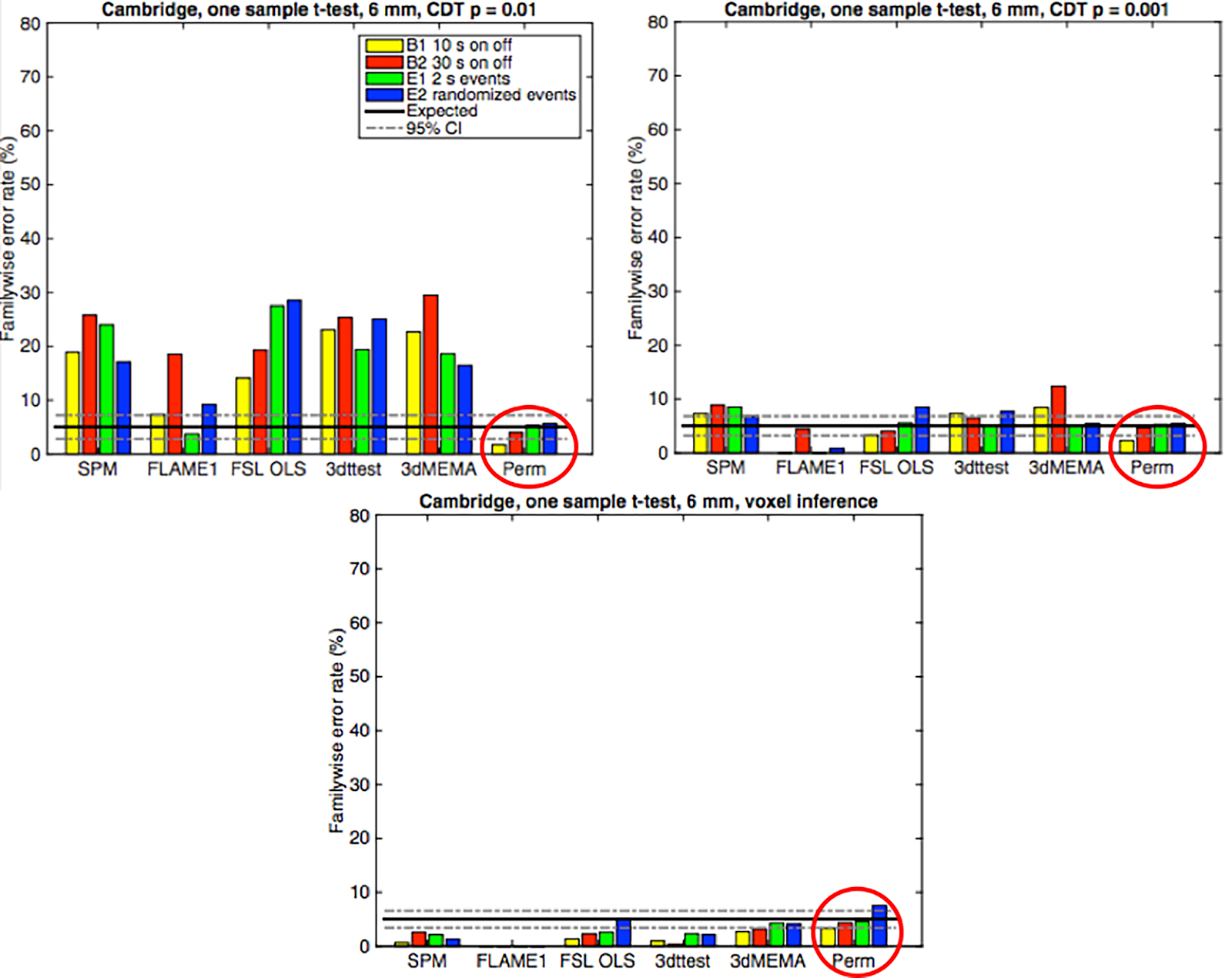 |
| Figure 1 from Eklund et al (2016). Simulations on an open-access dataset for different block and event-related designs. Upper left: Cluster-defining threshold (CDT) of p = 0.01 uncorrected; upper right: CDT of p = 0.001 uncorrected; bottom: voxel-level inference. Black line: Expected false positive rate of 5%. A threshold of p = 0.01 leads to inflated false positives across all of the major software packages (SPM, AFNI, and FSL), while a threshold of p = 0.001 leads to clusters closer to the expected 5% false positive rate. Voxel-level inference is slightly conservative in all cases. Permutation testing (circled in red), a nonparametric method, does as expected under all conditions. |
*Or not.
Solutions
There are three solutions to this problem; solutions to make neuroimaging respectable again, to cease being laughed at as cranks, charlatans, raiders of the public fisc, and attention-seeking, unscrupulous bloggers.
One solution is to use voxel-wise thresholds; although, as shown in the Eklund paper, these are often far too conservative, and can lead one to conclude there are no results when they actually do exist. I, for one, cannot stand the thought of those poor results slowly suffocating in their little gray coffins, alive but unable to signal for help. With voxel-wise thresholds we stop up our ears with wax; we think we hear the dim scratching of nails, the whimpers for succor, but dismiss them as figments of a fevered imagination; and we leave those tiny blobs and their tiny blob families to know that their last moments will be horror.
The second, more humane solution is to use more conservative cluster-forming thresholds, such as p = 0.001 uncorrected, in conjunction with more accurate modeling of the spatial autocorrelation. I recommend updating your AFNI binaries to the latest version (i.e., the beginning of 2017 or later), and using the -acf option in 3dFWHMx. For example:
3dFWHMx -mask mask+tlrc.HEAD -acf tmp.txt errts+tlrc.HEAD
Which will generate parameters for a more accurate estimation of the empirical ACF; you will see something like this:
++start ACF calculations out to radius = 37.68mm
+ACF done (0.74 CPU s thus far)
11.8132 13.748 12.207 12.5629
0.260939 6.36019 16.6387 19.1419
The first line of numbers are the traditional smoothness estimates in the x-, y-, and z-directions, as well as a weighted average of them (bolded). The second line of numbers are the a, b, and c parameters for the ACF model,
a^(-r*r/(2*b*b))+(1-a)^(-r/c)
With the last number being an updated estimate of the smoothness. These are then input into 3dClustSim:
3dClustSim -acf 0.26 6.36 16.64 -mask mask+tlrc.HEAD -athr 0.05 -pthr 0.001
The difference between the two smoothness estimates leads to substantial differences in significant cluster thresholds. In this case, the traditional estimates lead to a cluster threshold of 668 contiguous voxels, while the ACF version gives a threshold of 1513. This was using an initial cluster-defining threshold of p = 0.01, which can lead to such large differences; more stringent thresholds (e.g., p = 0.001) have less of a difference, but still a significant gap between them.
The third solution is to use non-parametric methods, such as permutation tests; which, since they do not rely on assumptions of normality, are immune to the autocorrelation assumptions listed above. Some popular tools include SPM's SnPM (Statistical non-Parametric Mapping); FSL's randomise; and Eklund's BROCCOLI. Out of the three, I've only used randomise, and found it straightforward to use (see the tutorial here).
Conclusions
Have we been profiting too long from dubious methods in neuroimaging? Have we become lax and complacent in our position as a period science, knowing that no matter how poorly designed the experiment is, no matter how ludicrous the question we are investigating - such as where the word YOLO is in the brain, or how the consumption of Four Loko affects delayed discounting - no matter whether our subjects are technically alive or not, we will probably still get a significant result, most likely in the precuneus?**
The answer to all of these, I would say, is yes. But just because I was able to get the results of my first paper to squeak by with an outdated version of AlphaSim, and consequently have an easy time in graduate school, make tons of money, and be envied by all of my friends, doesn't mean that you should have the same privilege. The way forward will be a hard one for the neuroimagers of today; standards will be higher, methods tighter, reviews harsher. But if you put in enough work, if you exercise enough diligence, and if you live long enough into the ninth year of your graduate program, you may just be able to take advantage of the next major statistical loophole that comes along. Have faith.***
**For the record, I still don't know where the precuneus is. My best guess is: "Somewhere right before the cuneus."
***In all seriousness, AFNI has been responsive, helpful, and, given the circumstances, even gracious with any issues that have come up with their programs - specifically, 3dFWHMx (the smoothness estimator) and 3dClustSim (the cluster threshold estimator). The problems are not so much with AFNI, as with how it is used; and even though it is being patched, it is worth keeping in mind that there will likely be other issues discovered in the future, as with all methods - even non-parametric ones. (Their response to the Eklund paper can be found here.) The responsibility of the user is to make sure that the results that are reported follow the most up-to-date correction methods; that suspicious-looking activations that don't make sense in the experimental context, or consist of several blobs connected by threads of voxels, should be interpreted with caveats; and that even results which are weak and do not pass correction with the current methods, may still be real but underpowered effects. As with any result, it's up to the researcher to use their best judgment.
Subscribe to:
Posts (Atom)